本地知识库说白了就是资料库的一种,比如说财务报表,销售记录,公司的规章制度等都属于本地知识库的范围;本地知识库的作用是把一个组织内部的资料梳理出来方便大家使用。所以,本地知识库的本质就是资料库;而这个资料库可以有多种不同的组织形式,比如以文档、表格、或者网页、视频、音频记录等形式存在,也可能是多种形式的混合。
我们需要先来了解两个模型的问题
生成式语言模型
随着自然语言处理(NLP)技术的迅猛发展,生成式语言模型在多种文本生成任务中表现卓越,尤其在语言生成和上下文理解方面。然而,纯生成模型在处理事实类任务时存在一些固有的局限性,这些模型依赖于固定的预训练数据,它们在回答需要最新或实时信息的问题时,可能会出现“编造”信息的现象,导致生成结果不准确或缺乏事实依据。此外,生成模型在面对长尾问题和复杂推理任务时,常因缺乏特定领域的外部知识支持而表现不佳,难以提供足够的深度和准确性。
检索模型
检索模型(Retriever)能够通过在海量文档中快速找到相关信息,解决事实查询的问题。然而,传统检索模型(如BM25)在面对模糊查询或跨域问题时,往往只能返回孤立的结果,无法生成连贯的自然语言回答。由于缺乏上下文推理能力,检索模型生成的答案通常不够连贯和完整。
RAG通过结合生成模型和检索模型的优势,实时从外部知识库中获取相关信息,并将其融入生成任务中,确保生成的文本既具备上下文连贯性,又包含准确的知识。这种混合架构在智能问答、信息检索与推理、以及领域特定的内容生成等场景中表现尤为出色。
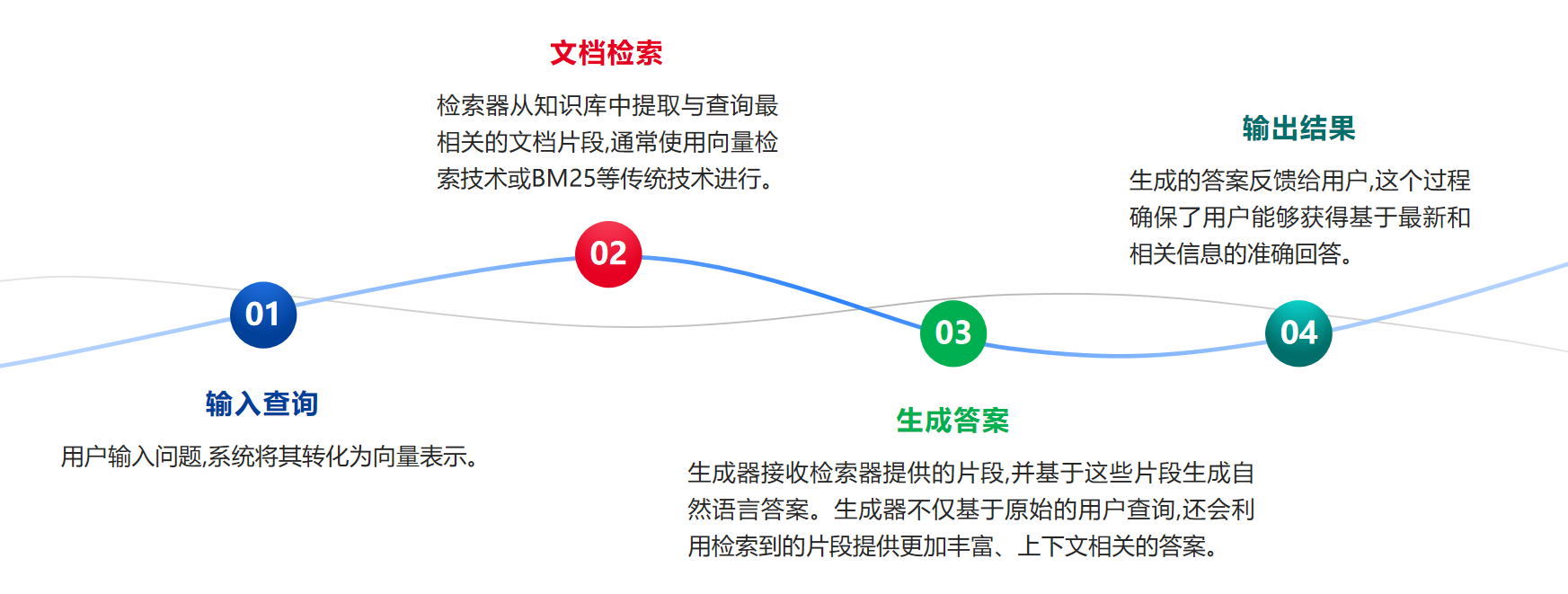
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合了信息检索与生成式大语言模型(LLM)的AI框架。
首先,检索器从外部知识库或文档集中获取与用户查询相关的内容片段
然后,生成器基于这些检索到的内容生成自然语言输出,确保生成的内容既信息丰富,又具备高度的相关性和准确性。
1. 检索器(Retriever)
检索器的主要任务是从一个外部知识库或文档集中获取与输入查询最相关的内容。在RAG中,常用的技术包括:
【向量检索】:它通过将文档和查询转化为向量空间中的表示,并使用相似度计算来进行匹配。向量检索的优势在于能够更好地捕捉语义相似性,而不仅仅是依赖于词汇匹配。
【传统检索算法】:主要基于词频和逆文档频率的加权搜索模型来对文档进行排序和检索。适用于处理较为简单的匹配任务,尤其是当查询和文档中的关键词有直接匹配时。
作用:RAG中检索器的作用是为生成器提供一个上下文背景,使生成器能够基于这些检索到的文档片段生成更为相关的答案。
2.生成器(Generator)
生成器负责生成最终的自然语言输出。在RAG系统中,常用的生成器包括:
【BART】:BART是一种序列到序列的生成模型,专注于文本生成任务,可以通过不同层次的噪声处理来提升生成的质量 。
【GPT等系列】:GPT是一个典型的预训练语言模型,擅长生成流畅自然的文本。它通过大规模数据训练,能够生成相对准确的回答,尤其在任务-生成任务中表现尤为突出 。
随着人工智能技术的飞速发展,特别是深度学习和自然语言处理领域的突破,数据的表示和应用方式发生了巨大的变化,非结构化数据如文字、图像、视频、音频等,无法直接通过传统数据库的表格形式来有效表达。为了高效处理这类数据,需要一种能够表示数据语义特征的方式——向量化技术。
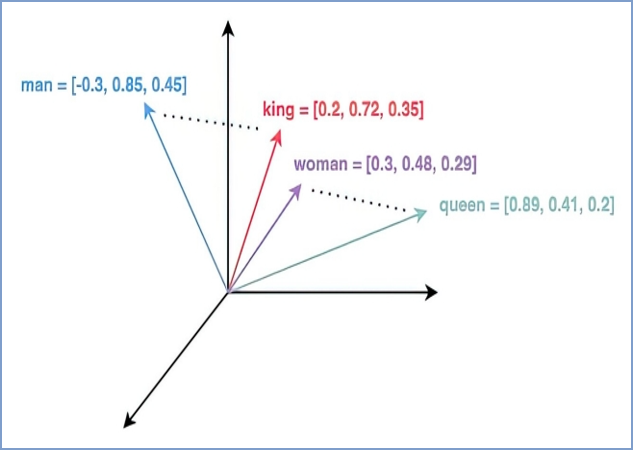
向量化——是指将复杂的对象(如文本、图片等)通过深度学习模型转化为固定长度的向量嵌入(embeddings)。这些嵌入保留了原始数据的重要特征,并且可以在数学空间中进行比较和操作。
嵌入模型——会将各种数据 (例如文本、图像、图表和视频) 转换为数值向量,以便捕捉其在多维向量空间中的含义和细微差别。通过将向量映射到多维空间,可以对向量的语义相似性进行细致的分析,从而显著提高搜索和数据分类的准确性。
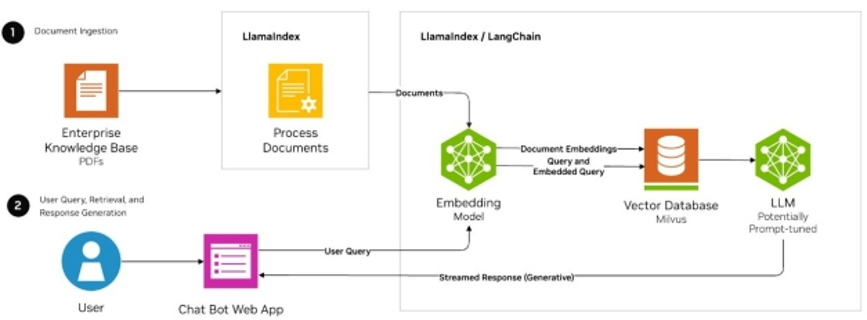
向量数据库(Vector Database)是专门设计用于存储、管理和检索高维向量的数据库系统,被广泛应用于自然语言处理、计算机视觉、推荐系统等需要处理复杂语义的场景。
向量数据库的核心目标是高效处理非结构化数据(如文本、图像、音频和视频)。文本、图像、音频、视频等非结构化数据,经过向量化处理后,转换为高维空间中的点,这些数据在向量空间中有着特定的位置关系,使得向量数据库能够基于这种关系进行快速、准确的相似性匹配。
传统数据库主要处理结构化数据,比如以行、列形式存储的表格数据。
向量数据库专注于处理非结构化数据(例如图片、文本、音频、视频),通过将这些数据转化为高维向量表示,从而捕捉其语义特征。
传统数据库采用行式存储(Row-based)或列式存储(Column-based),数值型与文本型数据被以预定义的固定模式存储。
向量数据库使用针对高维数据优化的存储和索引结构
传统数据库的检索请求基于精确查询或条件匹配,匹配主要依赖关键字、主键、索引等机制,适用于精确查找。
向量数据库的检索重点是相似度计算,它通过高维向量的距离(如欧几里得距离、余弦相似度)进行“模糊匹配”,实现语义级相似性搜索
传统数据库广泛应用于事务处理(OLTP)和数据分析(OLAP)场景,强调数据的准确性和一致性。
向量数据库主要用于人工智能和大数据领域,对非结构化数据进行高效的语义理解和相似性匹配的场景。
OPEN AI:text-embedding-ada-002
经典的通用模型,性能稳定,广泛应用于各类场景。
Google:Gemini Embedding 2
最新一代多模态嵌入模型,支持文本、图像、音频等多种输入,在跨模态检索方面表现卓越。
BAAI:bge-m3
中文表现优异的开源模型,支持多种语言,性能强大。
Nomic:nomic-embed-text-v1.5
开源模型中的新秀,以其高性价比和出色的性能受到关注。
阿里巴巴:Qwen3-Embedding
专为中文场景优化的模型,在中文语义理解上表现出色。
Moka AI m3e-base
另一个专注于中文的优秀开源模型,轻量且高效。
在企业 AI 解决方案的网络中部署 LLM 时面临的一个重大挑战是幻觉现象。在这些情况下,LLM 产生的响应虽然看起来逻辑上连贯且合理,但与事实不符,不准确。这个问题危及企业决策过程的准确性,并会降低人工智能驱动的洞察力的可靠性。
借助 RAG,LLM 在提示的上下文窗口中获得额外的指令和相关数据块,以提供更明智的响应,从而减少错误信息,但不能消除幻觉。
当 LLM 接收到查询时,它不仅依赖于自身的预训练知识,还会主动从指定的知识源检索相关信息。这种方法确保了生成的输出能够参考大量上下文丰富的数据,并得到最新、最相关可用信息的支持。
检索器(Retriever):
功能:在知识库或大规模文档集中搜索与查询主题高度相关的信息。
工作方式:识别在语义上与查询相关的文档,并通过相似度度量(通常采用向量间的余弦相似度)计算相关性。
生成器(Generator):
定义:通常是一个大型语言模型。
输入:检索到的相关信息和原始查询。
输出:基于输入生成响应。
知识库(Knowledge Base):
用途:作为检索器查找文档或信息的数据源。
工作原理
当 LLM 接收到查询时,它不仅依赖于自身的预训练知识,还会主动从指定的知识源检索相关信息。这种方法确保了生成的输出能够参考大量上下文丰富的数据,并得到最新、最相关可用信息的支持。
工作流程
知识库准备:
对文档进行索引,创建文本嵌入
检索器模型:
训练或微调,以有效搜索知识库,
生成器模型:
通常采用预训练的语言模型
系统集成:
确保各组件无缝协作
工作原理
Graph RAG 基于知识图谱(KGs)构建。知识图谱是现实世界实体及其关系的结构化表示,主要由两个基本元素组成:
节点(Nodes):表示单个实体,如人物、地点、物体或概念。
边(Edges):表示节点之间的关系,定义了实体间的连接方式。
相比于标准 RAG 使用向量相似度和向量数据库进行检索,Graph RAG 利用知识库进行更全面、系统的信息检索,从而提高了检索的完整性和准确性。
工作流程
查询处理:
对输入查询进行分析和转换,使其适合图结构的查询格式
图遍历:
系统在图结构中进行探索,沿相关关系路径寻找连接的信息节点
子图检索:
不同于检索独立的信息片段,系统提取包含相互关联上下文的相关子图
信息整合:
将检索到的子图进行组合和处理,形成一个连贯、全面的上下文信息集
响应生成:
语言模型基于原始查询和整合后的图信息生成最终响应
工作原理
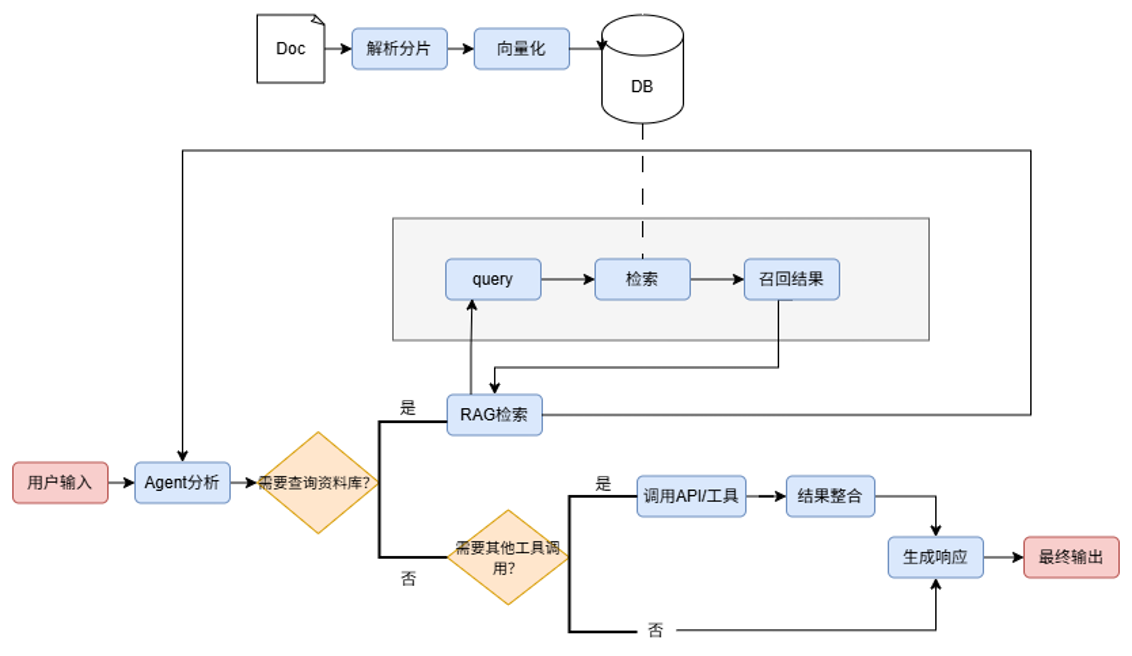
Agentic RAG 就是 “主动思考 + 解决问题”。它给 AI 加了一个 “自主智能体”,就像让 AI 有了自己的思维:能自己拆解复杂问题、动态调整找答案的方式、调用各种工具(比如地图、数据库、计算器),还能从经验中学习。
工作流程
Agentic RAG 的工作不是固定步骤,而是一个 “感知 – 思考 – 行动 – 学习” 的循环
理解需求:读懂你的核心诉求
拆解任务:把复杂问题拆成小任务
动态检索:针对每个小任务选最合适的方式找信息
调用工具:用外部工具核实信息
整合验证:把所有信息汇总,检查关键信息是否准确
生成学习:给出最终方案,记住你的反馈,下次优化

